# 핵심 코드 정리
| Source Code | 설명 | Data Type | Comment |
|
import numpy as np
|
|||
|
np.array(list, dtype=)
|
{numpy.ndarray} 객체 생성 | numpy.ndarray | numpy는 하나의 data type만 가능 |
| {np.ndarray}.dtype | {numpy.ndarray}의 dtype 변수 반환 | numpy.dtype | "np data type" 구글에 검색 |
*{np.ndarray}: numpy의 ndarray 객체를 의미하며 어떤 형태는 반환되는 결과가 {np.ndarray} class라면 적용 가능한 code임을 말한다.
numpy.ndarray 객체 생성
수치 자료 분석을 위해서는 분석을 하고자 하는 데이터를 python에 load 시키는 과정이 필요합니다. 대부분의 경우 만들어진 데이터를 read 기능을 이용하여 불러오는 것이 일반적이지만, 직접 자료를 python 대화형 인터프리터나 코드 편집기에 입력해야될 때도 있습니다.
가장 기본적인 데이터 객체 생성 방법부터 알아보겠습니다. 기본 선언 문법의 구조는 아래와 같습니다.
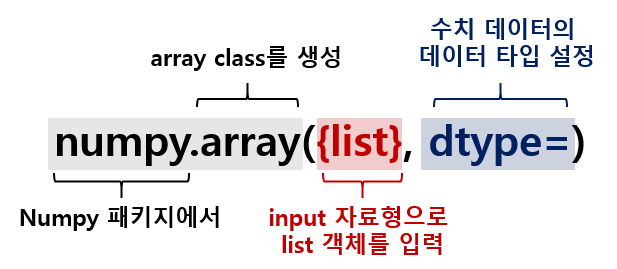
numpy.array({list}, dtype=)
위의 명령어를 해석하면 아래의 그림과 같습니다.
|
class numpy():
def array(list, dtype):
print("{}를 input으로 하는 {} 자료형의 numpy.ndarray 생성".format(list, dtype))
numpy.array([1, 2, 3, 4, 5], dtype=int)
|
굳이 표현하자면 이런 느낌일까요? numpy는 패키지고 array가 class라는 차이점만 뺀다면...
Numpy 패키지를 이용한 데이터 분석에서 데이터는 {numpy.ndarray}라는 type을 갖는 객체로서 선언되며, 이때 객체를 선언하기 위해서는 numpy.array({list}, dtype=) 구조의 명령어를 사용해야 합니다. 이때 input 데이터로는 list 타입의 객체를 입력하며 사용할 수치 데이터의 데이터 타입(dtype)을 설정할 수 있습니다. 설정 가능한 dtype 목록은 아래에서 확인 가능합니다.
https://numpy.org/doc/stable/reference/arrays.dtypes.html
Data type objects (dtype) — NumPy v1.22 Manual
The generic hierarchical type objects convert to corresponding type objects according to the associations: Deprecated since version 1.19: This conversion of generic scalar types is deprecated. This is because it can be unexpected in a context such as arr.a
numpy.org
Numpy를 이용한 데이터 분석을 처음 접하시는 분들이라면 보통 정수형 데이터나 부동소수점형 데이터가 많이 익숙하실텐데요, 그럴땐 데이터 타입을 아래와 같이 설정하시면 됩니다.
numpy.array({list}, dtype=int) # int32, 즉 32비트 정수형으로 dtype 설정
numpy.array({list}, dtype=float) # float64, 즉 64비트 정수형으로 dtype 설정
이때 특정 비트수의 dtype을 설정하기 위해서는 아래와 같이 설정하시면 됩니다.
numpy.array({list}, dtype=numpy.int16) # int16, 즉 16비트 정수형으로 dtype 설정
numpy.array({list}, dtype=numpy.float32) # float32, 즉 32비트 정수형으로 dtype 설정
기본적인 문법은 설명드렸으니, 아래와 같이 코드를 직접 시행하여 {numpy.ndarray} 객체를 선언해봅시다.
Code #1-1
|
import numpy as np
x = np.array([1, 2, 3, 4, 5])
print(x)
print(type(x))
print(x.dtype)
|
결과)
| [1 2 3 4 5] <class 'numpy.ndarray'> int32 |
해설)
| import numpy as np x = np.array([1, 2, 3, 4, 5]) |
numpy 패키지를 import하되, 사용시 이름을 np로 설정합니다. list 자료형 [1, 2, 3, 4, 5]를 input으로 하여 np.array class를 선언하고 이를 변수명 x에 할당합니다.
| print(x) # [1 2 3 4 5] print(type(x)) # <class 'numpy.ndarray'> print(x.dtype) # int32 |
x를 출력합니다. 출력 결과가 list와 비슷해 보이지만, 쉼표(,)로 구분되어있지 않다는 점이 특이합니다. 이때 x의 type을 확인해보면 {numpy.ndarray}라는 class로 되어 있는 것을 확인할 수 있습니다. 따로 dtype을 설정하지 않았고 input list의 모든 원소들이 정수이기 때문에 dtype은 int32로 되어 있습니다. x.dtype에 대해 추가로 설명드리자면
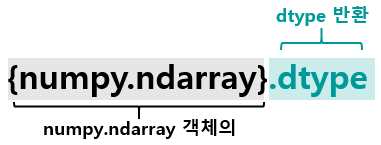
어떤 {numpy.ndarray} 객체(class)의 데이터 타입을 확인하기 위한 변수(variable)로, int32는 x라는 변수명에 바인딩 되어 있는 {numpy.ndarray} 객체의 데이터 타입이 {numpy.dtype[int32]}임을 의미합니다. 자세히 알아 둘 필요는 없고, 어떤 {numpy.ndarray} 객체의 데이터 타입을 확인하기 위해서는 {numpy.ndarray}.dtype 변수를 확인해보면 된다는 것만 아시면 될 것 같네요.
Code #1-2
|
x = np.array([1, 2, 3, 4, 5.1])
print(x)
print(x.dtype)
|
결과)
| [1. 2. 3. 4. 5.1] float64 |
해설)
| x = np.array([1, 2, 3, 4, 5.1]) |
이번에는 input list에서 마지막 숫자를 5.1로 바꿔보았습니다. 선언된 {numpy.ndarray} 객체를 변수 x에 할당합니다.
|
print(x) # [1. 2. 3. 4. 5.1]
print(x.dtype) # float64
|
x를 출력해보면 선언된 {numpy.ndarray} 객체의 모든 값들이 Code #1-1과는 다르네 모두 1., 2., ...와 같이 float으로 변환되었습니다. 여기서 {numpy.ndarray} 객체의 중요한 특징을 알 수 있는데요, {numpy.ndarray} 객체는
"모두 같은 dtype의 데이터만을 취급"
한다는 것입니다. Input list의 원소(element) 중 단 하나만 float type 숫자가 되면 int type 숫자가 있더라도 이를 강제로 float type으로 변환하여 {numpy.ndarray} 객체로 선언됩니다. 때문에 아래와 같은 code도 가능합니다.
Code #1-3
import numpy as np 생략
|
x = np.array(["1", "2", 3, 4, 5.1], dtype=int)
print(x)
print(x.dtype)
|
결과)
| [1 2 3 4 5] int32 |
해설)
| x = np.array(["1", "2", 3, 4, 5.1], dtype=int) |
이번에는 input list에 "1", "2"와 같은 str 자료형과, 3, 4와 같은 int 자료형, 5.1과 같이 float 자료형 모두가 포함되어 있습니다. 그리고 dtype=int로 설정해주었습니다. 이는 아래와 같이 변환되어 {numpy.ndarray} 객체가 생성된다고 생각하시면 받아들이기 쉬울 것 같습니다.
|
x = np.array([int("1"), int("2"), int(3), int(4), int(5.1)])
|
Code #1-4
import numpy as np 생략
|
x = np.array(["1", "2", 3, 4, 5.1, "abcdefg"], dtype=str)
print(x)
print(x.dtype)
|
결과)
| ['1' '2' '3' '4' '5.1' 'abcdefg'] <U7 |
해설)
| x = np.array(["1", "2", 3, 4, 5.1, "abcdefg"], dtype=str) |
Input list에 복합적인 자료형을 갖는 element들이 포함되어 있습니다. dtype=str로 설정하였지만 사실 이 부분을 생략해도 같은 결과를 얻게 됩니다.
|
print(x) # ['1' '2' '3' '4' '5.1' 'abcdefg']
print(x.dtype) # <U7
|
x에 할당된 {numpy.ndarray} 객체를 출력해보면 전부 str 자료형으로 변환되어 있는 것을 확인할 수 있습니다. 이때 x의 dtype은 '<U7'과 같이 표기되는데 이는 7개의 철자를 가진 유니코드 문자열임을 말합니다. 'abcdefg'가 가장 긴 철자를 갖는 str 자료형이라서 7개 철자 기준으로 생성되는 것입니다.
Code #1-5
import numpy as np 생략
|
x = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
print(x)
|
결과)
| [[ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12]] |
해설)
|
x = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
|
앞선 Code #1-1부터 Code #1-3 까지는 모두 단순 list들로 {numpy.ndarray} 객체를 만들었다면, 이번에는 좀 더 복잡한 형태의 {numpy.ndarray} 객체를 선언해보았습니다. Input list는
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
의 형태로 이를 input으로 선언된 {numpy.ndarray}의 객체는 2차원 배열 구조를 갖게 됩니다. Code #1-1과의 차이를 그려보면

와 같이 행렬의 형태로서 데이터 분석이 이루어지게 됩니다. 이때 제가 np.array([1, 2, 3, 4, 5])의 결과에 괄호를 치지 않았음에 유의해주시면 좋을 것 같습니다. 왜냐면 아래 두 {numpy.ndarray} 객체는 다른 차원을 갖기 때문입니다.
Code #1-6
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5])
y = np.array([
[1, 2, 3, 4, 5]
])
print(x)
print(y)
|
결과)
| [1 2 3 4 5] [[1 2 3 4 5]] |
둘의 차이는 아래 그림과 같습니다.

뒤에서 다루겠지만 위의 두 {numpy.ndarray}는 엄연히 다릅니다. 변수 y에 할당된 {numpy.ndarray} 객체는 2차원 행렬 데이터로 데이터 형태 자체는 하나의 행으로 구성된 1차원 데이터처럼 보이지만 실제로 (다음 장에서 배울) ndim 변수를 확인해보면 2를 반환합니다.
다음과 같이 3차원 tensor 데이터 형태도 가능합니다.
Code #1-7
import numpy as np 생략
|
x = np.array([
[
[1, 2, 3],
[4, 5, 6]
],
[
[4, 5, 6],
[7, 8, 9]
],
[
[7, 8, 9],
[10, 11, 12]
]
])
print(x)
|
결과)
| [[[ 1 2 3] [ 4 5 6]] [[ 4 5 6] [ 7 8 9]] [[ 7 8 9] [10 11 12]]] |
해설)
|
x = np.array([
[
[1, 2, 3],
[4, 5, 6]
],
[
[4, 5, 6],
[7, 8, 9]
],
[
[7, 8, 9],
[10, 11, 12]
]
])
|
길고 복잡하게 생겼지만, 2x3 행렬이 세 개 겹쳐진 것으로 이해하면 됩니다.

이외에도 좀 더 다차원 형태의 {numpy.ndarray} 객체도 선언할 수 있습니다.
'Python-데이터 분석 > Python-Numpy' 카테고리의 다른 글
| Python-Numpy 1-2. {numpy.ndarray} 자료 확인 및 변환 (0) | 2022.03.15 |
|---|