# 핵심 코드 정리
| Source Code | 설명 | Data Type | Comment |
|
import numpy as np
|
|||
| {np.ndarray}.shape | {numpy.ndarray}의 형태를 tuple로 반환 | tuple | (row, column) 1차원 행벡터: (row, ) 3차원 tensor: (z, row, column) |
| {np.ndarray}.ndim | {numpy.ndarray}의 차원을 int로 반환 | int | 1차원 행벡터: 1 2차원 행렬: 2 3차원 tensor: 3 |
| {np.ndarray}.size | {numpy.ndarray} 데이터의 수를 int로 반환 | int | {numpy.ndarray}.shape 내 모든 숫자의 곱 |
| {np.ndarray}.nbytes | {numpy.ndarray} 객체의 메모리 크기 반환 | int | 같은 data라도 설정한 data type에 따라 차지하는 용량이 달라질 수 있다. |
|
{np.ndarray}.tolist()
|
{numpy.ndarray}의 데이터들을 list로 반환 | list | 1차원 행벡터의 경우 단순 list로 변환 |
|
list({np.ndarray})
|
{{numpy.ndarray}의 데이터들을 list로 반환 | list | 1차원 행벡터의 경우 단순 list로 변환 |
*{np.ndarray}: numpy의 ndarray 객체를 의미하며 어떤 형태든 반환되는 결과가 {np.ndarray} class라면 적용 가능한 code임을 말한다.
numpy.ndarray 객체 정보 확인
Numpy 패키지를 이용한 데이터 처리를 하기 위해서는 데이터를 우선 python에 입력하는 것이 필요합니다. 앞선 글에서 말씀드렸듯 numpy.array 코드를 통해 데이터를 직접 입력할 수도 있지만 대개는 보통 어딘가에서 자료를 받거나 이미 저장되어 있는 데이터를 python에서 read하여 데이터 처리를 시작하는 것이 기본일 것입니다. 이때 python에 불러온 {numpy.ndarray} 객체가 매우 많은 데이터를 포함하고 있을 경우 한 눈에 데이터가 어떻게 생겼는지, 얼마나 많은지 등을 파악하기가 어렵게 됩니다. 이러한 상황에서 데이터의 정보를 확인해볼 수 있는 코드들을 알아보고자 합니다.
{numpy.ndarray}.shape
첫 번째 {numpy.ndarray} 객체에 바인딩 된 변수 shape입니다. {numpy.ndarray}의 행과 열의 수로 구성된 tuple을 반환합니다. {numpy.ndarray} 객체에 사용할 수 있기 때문에 어떤 형태든 반환되는 결과가 {np.ndarray} class라면 적용 가능함을 인지하고 있어야 합니다.
Code #2-1
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5])
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
print(x.shape)
print(y.shape)
print(z.shape)
|
결과)
| (5,) (2, 3) (2, 2, 4) |
해설
| x = np.array([1, 2, 3, 4, 5]) |
위와 같이 하나의 list를 input으로 받아서 선언되는 {numpy.ndarray} 객체는 1차원 행벡터로 간주됩니다. 1차원이기 때문에 행의 숫자는 무의미 하며, 열의 숫자로만 shape을 전달합니다. 그 결과는 (5,)라는 tuple 객체입니다.

|
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
|
변수 y에 할당된 {numpy.ndarray} 객체는 2차원 행렬 데이터로 2개의 행과 3개의 열을 가지고 있습니다.

|
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
|
z에 할당된 {numpy.ndarray} 객체는 2차원 행렬 데이터가 두 개 쌓인 3차원 tensor 형태 입니다. [[1, 2, 3, 4], [5, 6, 7, 8]]이라는 2차원 행렬과 [[4, 5, 6, 7], [8, 9, 10, 11]] 두 개의 행렬이 합쳐져 있습니다. 두 행렬은 (2, 4)의 shape을 가지며 쌓여있습니다.
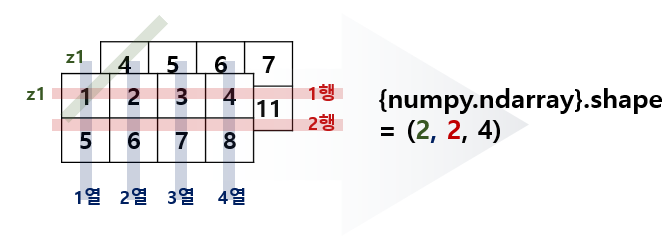
이와 같이 차원이 하나 늘어날 수록 해당 차원(n)에 쌓인 (n-1)차원의 {numpy.ndarray} 객체의 수가 n차원 shape의 가장 앞에 나타나게 됩니다. 이를 응용하면 더 높은 차원을 갖는 {numpy.ndarray}의 shape도 알 수 있습니다. 다음 Code의 결과를 예측해볼까요?
Code #2-2
import numpy as np 생략
|
x = np.array([[1, 2, 3, 4, 5]])
print(x.shape)
|
결과)
| (1, 5) |
앞 장에서 말씀드렸듯, 괄호로 두 개 쌓여져 있으면 2차원 행렬 취급한다고 했습니다. 한 개의 행과 5개의 열로 이루어져 있으므로 {numpy.ndarray}.shape은 (1, 5)를 반환합니다.
물론 문제를 풀기 위해서는 어떤 {numpy.ndarray}의 shape이 어떻게 되어 있는지 맞추는 것도 중요합니다만, 보통은 python에 불러온 {numpy.ndarray} 객체가 매우 많은 데이터를 포함하고 있을 경우, {numpy.ndarray}.shape 변수를 불러와 해당 {numpy.ndarray} 객체가 어떤 shape을 갖고 있는지 확인할 때 사용합니다. 뒤에서 다룰 {numpy.ndarray} 객체의 연산이 이뤄지기 위해서는 무엇보다도 {numpy.ndarray} 객체의 shape 일치 여부가 매우 중요해지기 때문입니다. 불러온 데이터 사이의 연산이 정의되는지를 확인하기 위해서라도 {numpy.ndarray}.shape은 꼭 확인합시다. 본 챕터의 제목이 "numpy.ndarray 객체 정보 확인"이라는 것을 잊으시면 안됩니다.
{numpy.ndarray}.ndim
두 번째 {numpy.ndarray} 객체에 바인딩 된 변수 ndim입니다. {numpy.ndarray}이 몇 차원인지를 나타내는 정수를 반환합니다. 마찬가지로 {numpy.ndarray} 객체에 사용할 수 있기 때문에 어떤 형태든 반환되는 결과가 {np.ndarray} class라면 적용 가능함을 인지하고 있어야 합니다.
Code #2-3
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5])
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
print(x.ndim)
print(y.ndim)
print(z.ndim)
|
결과)
| 1 2 3 |
해설
| x = np.array([1, 2, 3, 4, 5]) |
1차원 행벡터 {numpy.ndarray}의 shape이 (5,)와 같이 데이터의 수 하나만을 갖고 있는 tuple 객체입니다. {numpy.ndarray}.shape의 원소의 개수가 1개 이므로 {numpy.ndarray}.ndim은 1을 반환합니다.
|
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
|
2차원 행렬 {numpy.ndarray}의 shape은 (2,3)와 같이 행과 열의 수로 구성된 tuple 객체입니다. {numpy.ndarray}.shape의 원소의 개수가 2개 이므로 {numpy.ndarray}.ndim은 2을 반환합니다.
|
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
|
3차원 tensor {numpy.ndarray}의 shape은 (2,2,4)와 같이 포함된 행렬의 수와 각 행과 열의 수로 구성된 tuple 객체입니다. {numpy.ndarray}.shape의 원소의 개수가 3개 이므로 {numpy.ndarray}.ndim은 3을 반환합니다.
{numpy.ndarray}.nbytes
세 번째 {numpy.ndarray} 객체에 바인딩 된 변수 nbytes입니다. {numpy.ndarray} 객체가 용량을 얼마나 차지하는지를 나타내는 수를 반환합니다. 마찬가지로 {numpy.ndarray} 객체에 사용할 수 있기 때문에 어떤 형태든 반환되는 결과가 {np.ndarray} class라면 적용 가능함을 인지하고 있어야 합니다.
Code #2-4
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5])
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
print(x.nbytes)
print(y.nbytes)
print(z.nbytes)
|
결과)
| 20 24 64 |
중요한 것은 {numpy.ndarray} 객체 생성시 지정해주는 dtype에 따라 {numpy.ndarray} 객체의 용량이 달라진다는 것입니다.
Code #2-5
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5], dtype=np.int64)
y = np.array([1, 2, 3, 4, 5], dtype=np.int16)
print(x.nbytes)
print(y.nbytes)
|
결과)
| 40 10 |
변수 x와 y 모두 [1 2 3 4 5]라는 정수형 데이터를 갖는 1차원 행벡터이지만, dtype에 차이가 있습니다. 이로 인해 {numpy.ndarray} 객체가 차지하는 용량이 달라지게 되는 것입니다.
numpy.ndarray 객체 변환
{numpy.ndarray}.tolist()
다음으로 {numpy.ndarray} 객체를 다른 자료형으로 변환하는 방법에 대해서 살펴보겠습니다. {numpy.ndarray}는 배열의 형태를 띄고 있기 때문에 list로 변환할 수 있는 메서드를 가지고 있으며 {numpy.ndarray}.tolist()와 같이 사용할 수 있습니다. 이때 각 행들을 list로 변환하며 다차원 {numpy.ndarray} 객체의 경우 이를 다시 원소로 하는 list를 반환합니다. 마찬가지로 {numpy.ndarray} 객체에 사용할 수 있기 때문에 어떤 형태든 반환되는 결과가 {np.ndarray} class라면 적용 가능함을 인지하고 있어야 합니다.
Code #2-6
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5])
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
print(x.tolist())
print(y.tolist())
print(z.tolist())
|
결과)
| [1, 2, 3, 4, 5] [[1, 2, 3], [4, 5, 6]] [[[1, 2, 3, 4], [5, 6, 7, 8]], [[4, 5, 6, 7], [8, 9, 10, 11]]] |
해설
| x = np.array([1, 2, 3, 4, 5]) print(x.tolist())
|
변수 x에 할당된 {numpy.ndarray} 객체는 1차원 행벡터로, tolist() 메서드 적용시 자연스럽게 [1, 2, 3, 4, 5]의 list를 반환합니다.
|
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
print(y.tolist())
|
변수 y에 할당된 {numpy.ndarray} 객체는 2차원 행렬로, [1 2 3]과 [4 5 6]을 각 행의 성분으로 포함하고 있습니다. tolist() 메서드 적용시 각 행을 list로 변환한 형태([1, 2, 3], [4, 5, 6])를 다시 원소로 삼는 list([[1, 2, 3], [4, 5, 6]])를 반환합니다.
|
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
print(z.tolist())
|
변수 z에 할당된 {numpy.ndarray} 객체는 3차원 tensor로, [[1 2 3 4] [5 6 7 8]]과 [[4 5 6 7] [8 9 10 11]] 두 행렬을 포함하고 있습니다. tolist() 메서드 적용시 각 행을 list로 변환한 형태([1, 2, 3, 4], [4, 5, 6, 8], [4, 5, 6, 7], [8, 9, 10, 11])를 각 행렬에서 다시 원소로 삼는 list([[1, 2, 3, 4], [5, 6, 7, 8]], [[4, 5, 6, 7], [8, 9, 10, 11]])를 다시 원소로 삼는 list([[[1, 2, 3, 4], [5, 6, 7, 8]], [[4, 5, 6, 7], [8, 9, 10, 11]]]))를 반환합니다.
list({numpy.ndarray})
마지막으로 {numpy.ndarray}는 배열의 특성, 즉 반복이 가능한 객체로 list() 함수를 적용할 수 있습니다. list({numpy.ndarray})와 같이 사용할 때 {numpy.ndarray}의 각 열들을 원소로 하는 list를 반환합니다. 이때 tolist() 메서드와 다른 점은 다차원 {numpy.ndarray} 객체의 경우 각 행을 {numpy.ndarray} 객체로 하여 list의 원소로 삼는다는 것입니다.
Code #2-7
import numpy as np 생략
|
x = np.array([1, 2, 3, 4, 5])
y = np.array([
[1, 2, 3],
[4, 5, 6]
])
z = np.array([
[
[1, 2, 3, 4],
[5, 6, 7, 8]
],
[
[4, 5, 6, 7],
[8, 9, 10, 11]
]
])
print(list(x))
print(list(y))
print(list(z))
|
결과)
| [1, 2, 3, 4, 5] [array([1, 2, 3]), array([4, 5, 6])] [array([[1, 2, 3, 4], [5, 6, 7, 8]]), array([[ 4, 5, 6, 7], [ 8, 9, 10, 11]])] |
위와 같이 python에 불러온 {numpy.ndarray} 객체에 대해 정보를 파악하는 방법(데이터의 모양, 차원, 용량)과 {numpy.ndarray} 객체를 다른 자료형인 list 타입의 자료로 변환하는 방법들에 대해서 알아보았습니다.
'Python-데이터 분석 > Python-Numpy' 카테고리의 다른 글
| Python-Numpy 1-1. 수치 자료 분석을 위한 데이터 생성 (0) | 2022.03.09 |
|---|